The transition from static Indoor Air Quality (IAQ) monitoring to active, intelligent intervention marks a pivotal shift in environmental health. By integrating the Global Open Indoor Air Quality Standards (GO IAQS) into an agentic AI framework, we are moving beyond simple data collection toward an “Agentic IAQ Consultant.” This article explores the technical and ethical journey of embedding a global standard within an AI agent to provide real-time, actionable insights for healthier indoor environments thanks to the inBiot implementation.
1. Beyond the data, toward empathetic air quality intelligence
Fueled by new regulations, HVAC optimization, ESG scoring, and workplace-health commitments, continuous monitoring is spreading fast. But continuous data without continuous interpretation and remediation is just a more expensive way to not act.
And even for someone who knows what the numbers mean, the standards landscape is fragmented, “scattered across various organizations and regions, and difficult to find and interpret” [1, GO AQS, 2025]. A consultant auditing against WELL, EPBD, and ASHRAE is cross-referencing three documents with different units, different averaging periods, and different compliance philosophies.
An empathetic AI agentic solution changes this: it can read sensor data, apply multiple standards at once, identify the dominant issue, and communicate findings in terms that connect to the person receiving them, not just operationally, but emotionally [2, Papathanasiou, 2026].
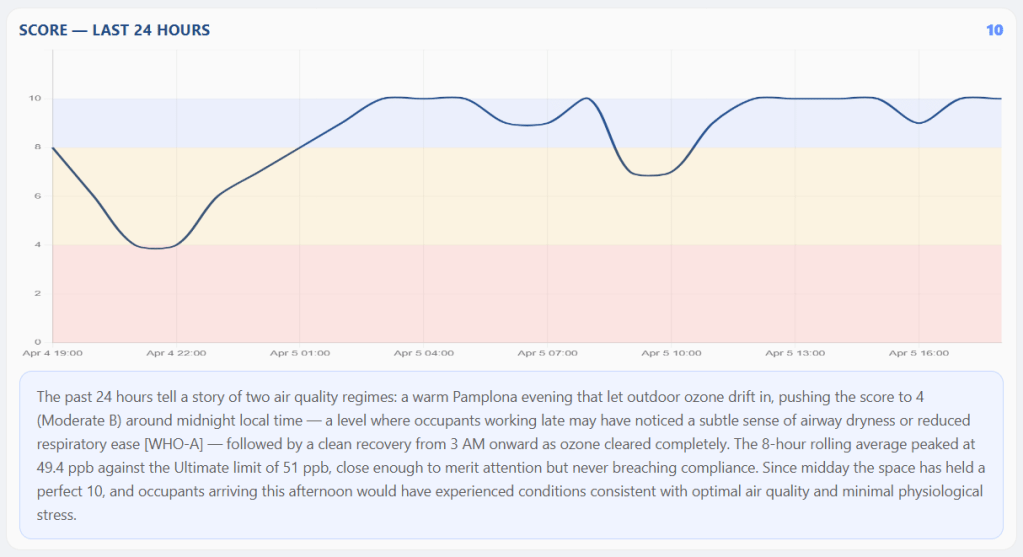
Figure 1: Anne delivers the GO IAQS score for the last 24 hours as a time series with natural language explanation. In this interaction, the empathy mode was activated before dashboard creation.
Designing for trust, not just accuracy
Having a human in the loop is not the same as having a human in control. Agudo et al. [3, Agudo et al., 2024] found that when people see an AI recommendation before forming their own view, their independent judgment is effectively compromised, even when the AI is wrong. Anne is built around that finding: she surfaces results first and asks for human context before suggesting any action. In a domain where a wrong call is not a UX failure but a compliance liability, and sometimes a clinical one, the sequence matters.
In default mode, Anne anchors every statement to what peer-reviewed research documents at that exposure level, not what the space probably feels like. The empathetic mode, available via “focus: empathetic,” adds a felt-experience narrative grounded in the human-AI empathy loop [4, Gu et al., 2026]. But it is flagged as inference and closes with a question: “Does this match what people in the space are reporting?”
The line between evidence and speculation is not a rhetorical choice. It is where the real design work lives, and where Anne can make a difference.

2. What an AI-powered GO IAQS assessment looks like
The principles above only matter if they survive contact with real data. Here is a session walkthrough showing Anne reasoning through the OODA loop (Observe – Orient – Decide – Act), with progressive human-in-the-loop interaction at each stage.
Steps 1-2 — Open session and trigger assessment
| The consultant types “Hi Anne,” gets a greeting banner with available sensors and skills, then triggers: /goiaqs main_office. One command, one device. The GO IAQS skill takes over. |
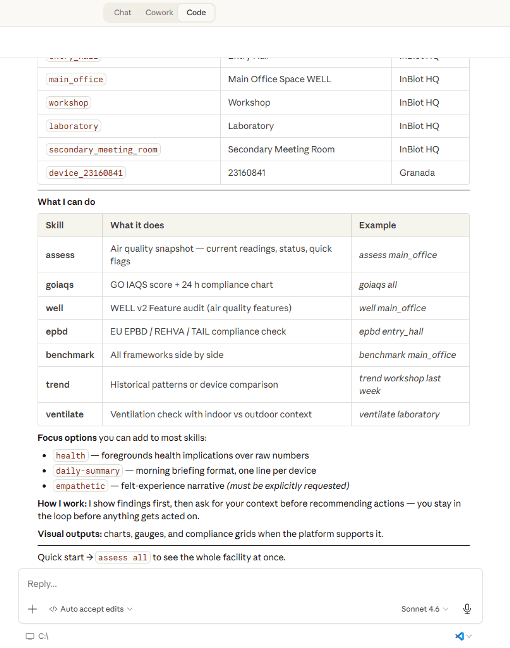
Step 3 — Anne presents findings (Observe + Orient)
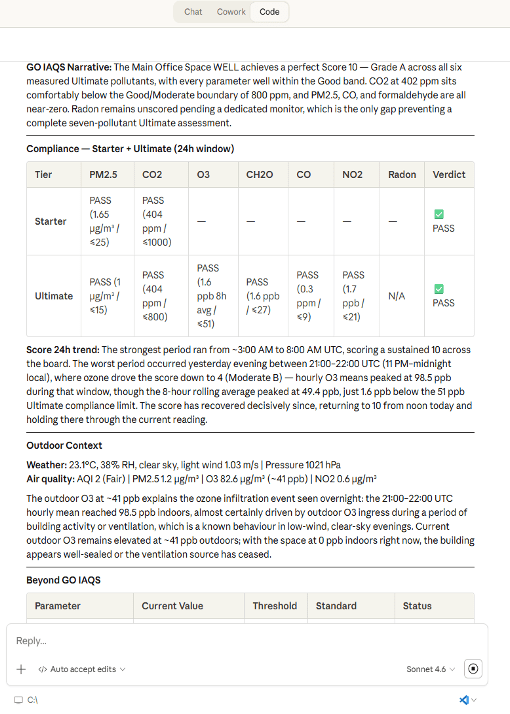
| Anne calls four tools via the MCP server (Model Context Protocol, the data layer described in Section 3): latest readings, GO IAQS score, 24-hour compliance, and outdoor snapshot. She presents per-pollutant sub-scores, overall grade, dominant pollutant, and trend. Observe + Orient: findings only, no recommendations yet. |
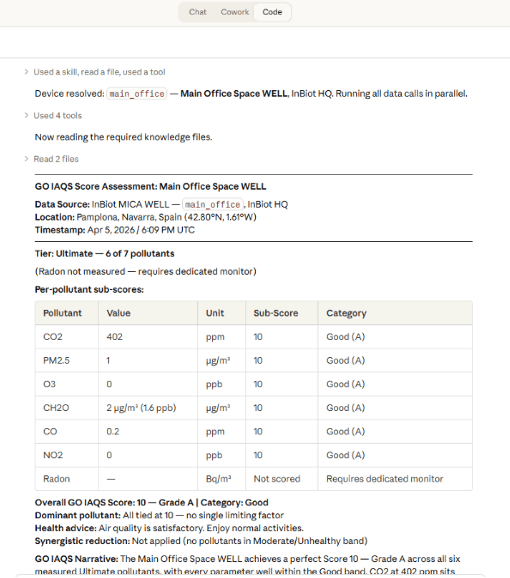
Step 4 — The human gate
| Anne stops. The human gate: the consultant adds what sensors cannot measure, things like occupancy, ventilation changes, audience, priorities. Because findings came without recommendations, the consultant’s judgment is not anchored to an AI suggestion. |

Steps 5-6 — Context in, recommendations out
| The consultant adds context, “focus on cost impact” or “focus: empathetic,” and Anne produces prioritized recommendations (Decide): for each pollutant exceeding its target, she shows the current value, the GO IAQS target, a specific action, and the projected score impact if that action is taken. She then generates a self-contained HTML dashboard the consultant can share directly with the facility manager or attach to an audit report (Act). |
Step 7 — The dashboard
| The dashboard follows the GO IAQS visual identity: blue for Good, amber for Moderate, red for Unhealthy. A facility manager sees a score, a grade, a color, a recommendation, and a 24-hour compliance timeline. Same data the consultant reviewed, repackaged so a non-specialist can act on it without reading the full assessment. |

3. Under the hood
Anne works with real-time sensor data (inBiot), outdoor weather feeds (OpenWeather), and CO2 forecasting (Chronos-2 on HuggingFace). Rolling averages, time-series aggregations, compliance scores – plenty of computation happens before anything touches the LLM. LLMs are not good with numbers, and most agentic systems fail on the data layer, not the AI.
The architecture is a plugin plus an MCP server, split so that numerical computation never depends on the language model. The plugin carries the domain logic: Anne’s persona, OODA reasoning, skills that orchestrate tool calls and knowledge files, and commands like /goiaqs and /well. The MCP server is a stateless data pipe with 14 tools across sensor data, outdoor context, CO2 forecasting, statistics, and the GO IAQS scoring engine. It knows nothing about Anne.
Where Anne V.1 departs from the standard stack
That separation matters because Anne V.1 departs from the standard agentic stack in two places:
- Deterministic scoring in the tool layer: anchor-table lookup, piecewise interpolation, worst-pollutant aggregation, synergistic reduction. Same concentrations, same score, every time. A 38-test suite covers band boundaries, edge cases, and known rounding traps. In this domain, a wrong threshold is a compliance failure.
- Skill-routed knowledge instead of RAG (retrieval-augmented generation): six markdown files, no vector database. For a system that advises on regulatory compliance, “probably the right document” is not good enough.
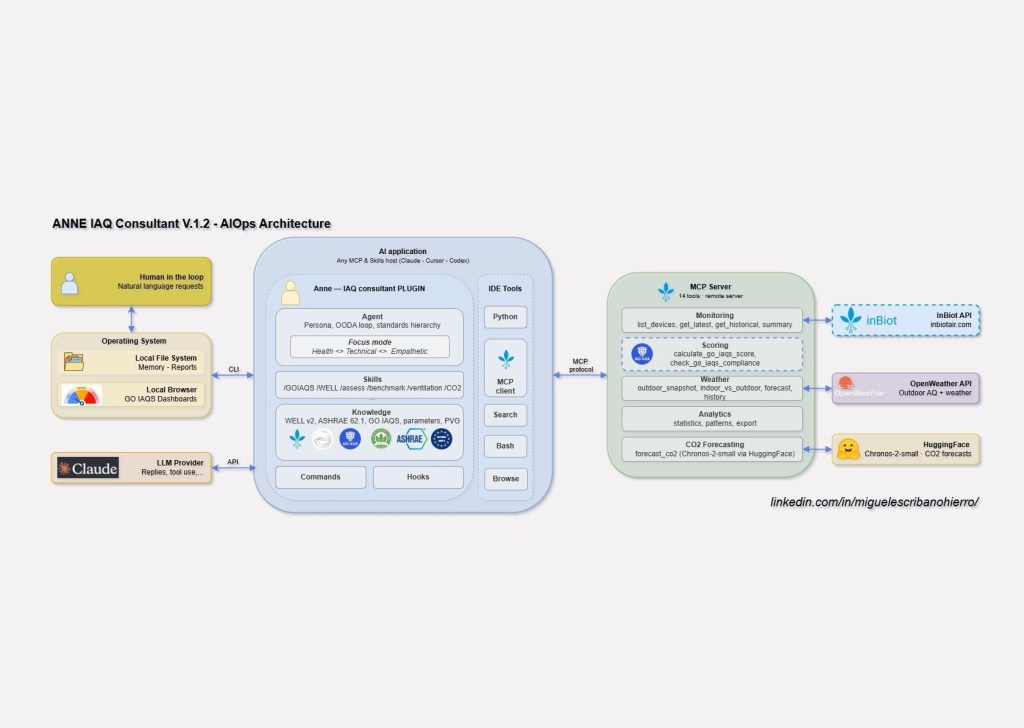
Figure 7: Architecture – three layers: MCP Server (tools, deterministic scoring) > Agent (persona, skills, knowledge, commands, hooks) > AI Client (Claude, Cursor, OpenAI…).
Disclaimer: This is a work-in-progress. Powered by real data from certified sensors. More evaluations are being deployed looking at LLM behavioural responses and calculations. The architecture aims at portability, explicability and ethical use of AI. GenAI is amazing. But it’s not magic. We let AI be cool and useful and problematic in realistic ways.
4. From White Paper to Code
The GO IAQS Score is fully deterministic, already machine-shaped (its scoring rules are numerical, unambiguous, and complete enough to implement directly): given the same sensor readings, every compliant implementation must produce the same result. The scoring engine implements three core steps from the White Paper: anchor-table lookup and piecewise interpolation (Appendix A formula), worst-pollutant aggregation, and synergistic reduction.
# Anchor tables — each tuple is (concentration, score).# Adjacent anchors 1 unit apart (e.g. 10→11, 800→801) mark the# transition between GO IAQS bands (White Paper, Appendix A).PM25_ANCHORS = [(0, 10), (10, 8), (11, 7), (25, 4), (26, 3), (100, 0)] # µg/m³CO2_ANCHORS = [(400, 10), (800, 8), (801, 7), (1400, 4), (1401, 3), (5000, 0)] # ppm# O3 and NO2 in ppb, CO in ppm, CH2O in ppb, radon in Bq/m³ — same shape.def interpolate(value: float, anchors: list[tuple]) -> int: """ Piecewise linear interpolation between anchor pairs → integer score [0, 10]. Below the first anchor → 10 (best). Above the last → 0 (worst). """ if value <= anchors[0][0]: return int(anchors[0][1]) if value >= anchors[-1][0]: return int(anchors[-1][1]) for (x0, y0), (x1, y1) in zip(anchors, anchors[1:]): if value <= x1: score = y0 + ((value - x0) / (x1 - x0)) * (y1 - y0) return clamp(round_half_up(score), 0, 10)
Figure 8: GO IAQS anchor tables for PM2.5 and CO2 (five more pollutants follow the same structure), and the interpolate() function implementing the Appendix A formula I = (Chigh − C)/(Chigh − Clow) · (Ihigh − Ilow) + Ilow.
5. Want to try it yourself?
This is a work in progress, not an open-source release. If you are an IAQ consultant, a sensor manufacturer, a building operator, or someone experimenting with agentic AI in the built environment, we are happy to walk you through a live session:
- Miguel Escribano (GO AQS Technical Member and inBiot Head of RevOps)
References
[1] GO AQS (2025). Global Open Indoor Air Quality Standards: A Unified Framework. White Paper v1.0, November 2025. ISBN 9798274916158. goaqs.org. CC BY-NC-SA 4.0.
[2] Papathanasiou, S. (2026). “Beyond the Gamification: Why 2026 Demands Empathetic AI for Air Quality.” See The Air, January 9, 2026. https://seetheair.org/2026/01/09/beyond-the-gamification-why-2026-demands-empathetic-ai-for-air-quality/
[3] Agudo, U., Liberal, K. G., Arrese, M., & Matute, H. (2024). The impact of AI errors in a human-in-the-loop process. Cognitive Research: Principles and Implications, 9(1), 3. https://doi.org/10.1186/s41235-023-00529-3 [4] Gu, J. et al. (2026). “The human-AI empathy loop: a path toward stronger human-AI relationships.” Science Bulletin, 71(4). https://doi.org/10.1016/j.scib.2025.10.027

Leave a comment